
Az OSPF (Open Shortest Path First) egy link-state protokoll, melyet az IETF Interior Gateway Protocol munkacsoportja fejlesztett ki elsôsorban a RIP hiányosságai miatt. 2. verziója az RFC1247-ben 1991 júliusában jelent meg és körülbelül ötször olyan terjedelmes, mint a RIP leírása. Valóban az OSPF bonyolult, ám sokkal kifinomultabb, kevesebb sávszélességet foglal, hurokmentes és számos más elônnyel rendelkezik a RIP-hez képest.
A link-state protokollok mûködése két részbôl áll. Elôször minden állomás felderíti a hálózat topológiáját, majd a kapott gráfban megkeresi a legrövidebb útvonalat és az ahhoz tartozó elsô állomást, amely felé továbbítani fogja a csomagot. Nyilvánvaló, hogy életbevágóan fontos, hogy a router-ekben levô topológia egyezô legyen és a legrövidebb út kiszámítása is mindenhol ugyanazon algoritmus szerint zajoljon, különben teljes káosz alakul ki. (Az A router B felé számítja a legrövidebb útvonalat, a B meg A felé és kész a galiba.) Az utóbbi feltétel könnyen teljesíthetô, ám a topológiai adatbázisok szinkronizálása komoly munkát igényel.
A hálózat topológiáját a link-ek állapotát leíró rekordok (link-state records) terjesztésével tudatják egymással az állomások. Az egyszerûség kedvéért egyenlôre ne tegyünk különbséget az állomások és a router-ek között.
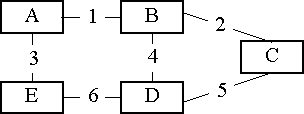
A fenti egyszerû, hálózat topológiai adatbázisa
12 rekordból áll, minden link-hez kettôbôl, hisz
a link mindkét végén levô állomás
létrehoz egy rekordot. A rekordokban szerepel a két
állomás, ami között a link fut, a link száma
és költsége is.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A link-ek állapotát leíró rekordokat idôbélyeggel látják el a router-ek, majd minden irányban terjeszteni kezdik. A kapott rekordokat feljegyzik saját topológiai adatbázisukba, az idôbélyeggel együtt, majd továbbadják. Ha olyan rekordot hallanak, amely már szerepel az adatbázisban és a hallott verziónál régebbi, akkor figyelmen kívül hagyják. Ezzel megakadályozzák, hogy egy-egy rekord örökké keringjen a hálózatban.
Ha egy link meghibásodik, errôl a két végén levô állomás értesül, és mindketten körbeadnak egy üzenetet, melyben jelzik, hogy a kérdéses link költsége végtelenre módosult, errôl mindenki értesül és a topológiai adatbázisok szinkronban maradnak.
Ha a hálózat kettészakad, a két rész képtelen egymást értesíteni a további változásokról. Példánkban az 1. és a 6. link meghibásodása után az A és E állomások már nem értesülhetnek a 2., 4. vagy 5. link hibájáról. Ennek természetesen semmiféle káros következménye nincs, minthogy az 1. és 6. link-ek költsége végtelen, így az A és E számára a B, C és D állomások úgyis elérhetetlenek, lényegtelen a köztük lévô link-ek állapota.

Más a helyzet azonban, ha az 1. link újra mûködôképes lesz. Errôl ugyan körbeküldenek az A és B router-ek egy üzenetet, azonban ez nem elég, hiszen ha idôközben például a 2. link állapota módosult, akkor A-ban errôl még a régi információ található. Éppen ezért az A és B állomások szinkronizálják adatbázisaikat. Ez azonban még mindig nem elég, E miatt, akivel szintén szinkronizálni kell. Megállapíthatjuk, hogy a topológiai változáskor körbeadott üzenet nem elégséges, ennél erôsebb szinkronizáció kell, amely célszerûen párokban zajlik.
A link-state módszernek több elônye is van a distance-vector protokollokkal szemben.
Egyrészt topológiai változás esetén a konvergencia gyors, hisz kis számú, rövid rekordot kell csak körbeadni a hálózatban, míg a distance-vector algoritmusok esetén egy link hibája számos célpontot érinthet és ez hosszú frissítô üzeneteket eredményezhet. Ráadásul a link-state algoritmus konvergenciája közben nem alakulhatnak ki hurkok.
Másrészt itt a költségek egyszerûbben tehetôk összetetté. Míg a distance-vetcor esetén a végtelen értékét alacsonyan kellett tartani, itt erre nincs szükség.
Harmadrészt a topológiai adatbázisból nem csupán egy, de több útvonal kiszámolható, melyek között megoszthatjuk a forgalmat, ez nem igényel további kommunikációt vagy memóriát, míg az EIGRP-ben levô multipath lehetôségek kihasználásához összes szomszédunk által terjesztett bejegyzéseket tárolni kell.
A multipath routing alatt két lehetôséget értük. Az egyik esetben csak akkor osztjuk meg a forgalmat több útvonal között, ha holtversenyben a legolcsóbbak. A második esetben a forgalom egy részét olyan útvonalra engedjük, amelyik nem a legolcsóbb, de még elfogadható. Mindkét megoldás esetén kisebb lesz a csomagok késleltetésének ingadozása, a több útvonal miatt az effektív sávszélesség is nagyobb és az egyik például a legolcsóbb útvonal kiesése esetén a forgalom mintázata nem annyira ugrásszerûen változik meg, hisz a csomagok egy része eddig is más útvonalon haladt.
Ha azonban nem csak a legolcsóbb utakat használjuk, hurkot hozhatunk létre a hálózatban. A fenti példában E állomástól C felé 2 útvonalat tekinthetünk. Az egyik a közvetlen és ennél kétszer drágább a B-n át vezetô. Ilyenkor a forgalmat valamilyen arányban, például kétharmad, egyharmad érdemes megosztani. B állomáson hasonló a helyzet, ott is két útvonal van, a közvetlen és a E-n át vezetô. A forgalmat ott is ilyen módon megosztva, annak egy része (az E felé irányított egyharmad harmada) vissza fog érkezni B-be. Ennek a visszaérkezett forgalomnak harmada ismét E felé távozik majd, a folyamat a végtelenségig tart. Igaz, hogy nagyon hosszú ideig csupán a forgalom igen kis százaléka kering a két állomás között, mégis a 4. link igen hamar torlódásossá válhat. A problémán úgy segíthetünk, ha csak olyan állomás felé továbbítunk csomagot, amelyik közelebb van a célhoz, mint mi, így attól nem kaphatunk vissza csomagot. A gyakorlatban azonban inkább csak a legjobb, de egyenlô költségû utak között szokás forgalmat megosztani, ez az EIGRP alapbeállítása is.
Maga az OSPF elnevezés onnan ered, hogy a kialakult topológiai gráfban a legrövidebb utat a Dijkstra nevéhez fûzôdô „legrövidebb utat elôre" (shortest path first, SPF) algoritmus szerint keresik a router-ek [5]. Ez egy igen hatékony O(N*log N) rendû algoritmus, ahol N a link-ek száma és ennyi idô alatt a gráfból az összes célponthoz meghatározza a legrövidebb utat.
Az OSPF elkülöníti az állomásokat és router-eket, hiszen csak az elôbbieken fut routing protokoll. Minthogy az egy link-en levô állomások teljesen egyformák a route-olás szempontjából azokat fölösleges megkülönböztetni, elég a link-et tekinteni. Az OSPF topológiai adatbázisában tehát nem állomások és router-ek közötti kapcsolatok, hanem router-ek és link-ek közötti kapcsolatok szerepelnek, a link-ek jelképezik az összes rájuk kapcsolt állomást. Az OSPF háromféle link-et különböztet meg.

A pont-pont link-ek nem jelentkeznek csúcsként az adatbázisban, hiszen ezeken a link-eken nincs állomás, így csomagok célpontjai sem lehetnek.
A router-ek felelôsek a saját link-state rekordjaik terjesztéséért, a link-ek link-state rekordjait pedig a link egyik kiválasztott router-e juttatja a hálózatba, ezeknek a rekordoknak a költsége mindig 0. A kiválasztott router meghatározása a Hello protokoll szerint, automatikusan történik. A külsô célpontok információit a hálózat szélén levô router-ek terjesztik.
Ha egy link-en több router is van, nem szükséges mindegyiknek, mindegyikkel szinkronizálnia adatbázisát, ez túl sok fölösleges kommunikációval járna. Ehelyett mindegyik csupán a kiválasztott router-rel ellenôrzi a szinkront és csak azzal szinkronizál eltérés esetén; könnyen belátható, hogy így bármely két router azonos adatbázisra fog eljutni. A kiválasztott router ilyenformán kitüntetett szerepet játszik, vele szinkronizálják adatbázisukat a többiek és ô a felelôs a link állapotát leíró rekord terjesztéséért. A kiválasztott router meghibásodása esetén új kiválasztott router-t kell választani és azzal minden router-nek szinkronizálni az adatbázisát. Ez a folyamat meglehetôsen hosszú idôt vesz igénybe, éppen ezért a kiválasztott router mellett tartalékot is választanak és nemcsak a kiválasztott, de a tartalék router-rel is szinkronizálják adatbázisukat. Így a kiválasztott kiesése esetén a tartalék azonnal a helyére léphet, a hálózat mûködése nem szünetel, mialatt új tartalékot választanak és azzal összeszinkronizálódnak.
Az OSPF 3 alprotokollból áll.
Mikor egy hálózatot üzembe helyezünk, a router-ek Hello csomagokat küldözgetnek egymásnak, melyben felsorolják azokat a router-eket, akikrôl ôk tudnak az adott link-en. Ily módon minden router azt is ellenôrizheti, hogy róla kik tudnak. A nem broadcast jellegû link-eken szükséges minden router-t a többi router címével konfigurálni, broadcast jellegû hálózaton a Hello protokoll ezt képes felderíteni.
A Hello csomagokban minden router egy elôre beállított prioritást is közzétesz magáról, a legnagyobb prioritású router lesz majd a kiválasztott. Azonban ha a kiválasztás után egy még nagyobb prioritású router kapcsolódik a link-re, a kiválasztás marad, mert a kiválasztott router változása költséges a sok újraszinkronizáció miatt. A frissen bekapcsolt router mindössze a kiválasztottal és a tartalékkal szinkronizálódik össze.
Maga az szinkronizáció az Exchange protokoll segítségével zajlik. Teljesen fölösleges lenne a teljes topológiai adatbázist lecserélni, hiszen a legtöbb esetben csak kis eltérések vannak. Éppen ezért elôször mindkét router leíró csomagokban közli a másikkal milyen bejegyzések milyen idôbélyeggel szerepelnek az adatbázisában. Ebbôl mindkét router kitalálhatja, hogy mely bejegyzések frissebbek a másikban és azokat felsorolja kérô csomagok formájában. A másik router pedig közönséges link-state rekordokkal válaszol, melyeket a vevô a Flooding protokoll szerint tovább terjeszt a hálózatban, mintha közönséges link-state frissítô rekordok lennének.
A Flooding protokoll terjeszti a link-state rekordokat, mûködése egyszerû: ha a vett rekordok frissebbek a mi adatbázisunkban szereplôknél, akkor módosítjuk az adatbázist és tovább terjesztjük a rekordokat. Ha nem, nem csinálunk semmit.
Bár eddig az egyszerûség kedvéért sorrendiséget követtünk, a valóságban a három protokoll egyidôben mûködik. Tehát egyszerre zajlik:
Az OSPF minden kommunikációja nyugtázott, az idôben befutó nyugta hiányában a csomagokat újraküldik, emiatt elôfordulhat, hogy a szinkronizációs folyamat elhúzódik és a közepén teljesen máshonnan egy link-state rekord érkezik. Ez nem befolyásolja a szinkronizációt, még ha a szinkronizációban frissítendô rekordot érint is, ha a rekord újabb, mint az ismert, akkor a szinkronizációtól függetlenül terjesztjük, még szinkronizációs partnerünknek is.
A kommunikáció ezenfelül hitelesített is, bár jelenleg csak nagyon egyszerû jelszavas hitelesítés definiált, mint a RIPv2-ben amit feltörni könnyû, ám a késôbbiekben bonyolultabb eljárások is integrálhatók a protokollba.
A régi bejegyzéseket célszerû eltávolítani a topológiai adatbázisokból. Ezt azonban a szigorú szinkronizációs követelmények miatt egyszerre kell minden router-nek megtennie. Éppen ezért minden rekord életkort is tartalmaz, ami 0-ról indulva másodpercenként nô és a rekord terjesztésekor ezt is továbbadjuk. Ha eléri élettartama végét egy órát, törlôdik az adatbázisból, de errôl a Flooding protokoll segítségével az egész hálózatot tájékoztatják, így minden router törölheti a rekordot.
Természetesen ha az adott rekord megfelel a valóságnak, akkor a kiöregedés elôtt meg kell újítani. Éppen ezért minden rekordot a Flooding protokoll segítségével, ha valamilyen más okból nem kell hamarabb, akkor 30 perc elteltével mindenképpen megismétlünk.
Nagyméretû hálózatok esetén a topológiai adatbázis mérete nagyobb lehet a kívánatosnál. Éppen ezért az AS-t több területre oszthatjuk fel. A Flooding protokoll csak a területek belsejében terjeszti a link-state rekordokat, a topológiai adatbázis csak egy területen belül egységes és csak a terület belsejének térképét tartalmazza. A területek egy kitüntetett területen keresztül érhetik el egymást, ez a gerinc. Minden területnek muszáj legalább egy ponton a gerincre kapcsolódnia. A területhatáron lévô router-ek összegzik a területükön található link-ekig vezetô utak költségét és ezt az összegzô információt terjesztik a gerincre. A gerinc többi router-e ezeket a gerincre küldött összefoglaló információkat továbbterjeszti a saját területére, de úgy, hogy hozzáadja a gerincen való áthaladás költségét is.

A fenti ábrán például a B router összegzi az 1. területen található összes link tôle való távolságát és ezt az információt a gerinc-területen belül a Flooding protokoll segítségével elterjeszti. Az E router az így megismert költségekhez hozzáadja a bc és a ce link-ek költségét és így terjeszti a 4. terület belsejében a Flooding protokoll segítségével. Ugyanezt az információt megkapja az A router-tôl is az af és ef link-eken át, ebben az esetben az 1. terület minden célpontjához 2 útvonal áll rendelkezésre, az egyik az A, a másik a B router-en át. Itt a distance-vector eljáráshoz hasonlóan a kisebbet választjuk és terjesztjük. Nem áll fenn azonban a hurok kialakulásának veszélye, hisz a területeken és magán a gerincben is egy link-state algoritmus választ utat, a distance-vector elem pedig egy teljesen hierarchizált helyzetben lép be: a csomag föllép egy területrôl a gerincre, majd onnan a cél-területbe lép. Itt hurok ki nem alakulhat.
Ha egy terület például az 1. kettészakad, de mindkét része kapcsolatban marad a gerinccel, akkor a topológiai adatbázisok szinkronizációja után a két router csak azokat a célpontokat fogja terjeszteni a gerincre, melyek az ô felében vannak. Így elkerülhetô az, hogy a területnek szóló csomagok rossz félbe kerülnek és így nem jutnak el a címzetthez. Ez a probléma már a RIPv1-nél fölmerült a subnet hiding módszerével kapcsolatban. Ha a gerinc szakad szét úgy, hogy egy területen keresztül megmarad még az összeköttetés (például, ha az ef link szakad meg, akkor az 1. területen keresztül képes még kommunikálni a 3. és a 4. terület), akkor az OSPF alaphelyzetben nem képes fenntartani a konnektivitást. Ezen a problémán segítendô létrehozhatunk az A és B router-ek között egy virtuális link-et, ami az 1. területen át vezet. Az ilyen link költsége kiadódik az 1. terület topológiájából. Ezt a link-et az A és B router link-state rekordban a Flooding protokoll segítségével terjeszteni fogja a gerincben, így ha az ef link megszakad, a gerinc összeköttetése megmarad, ezen a virtuális link-en keresztül. A gerincen átküldött csomagok (például E-tôl F-nek) pedig valójában elhagyják a gerincet. A virtuális link azonban nemcsak hiba esetén kerülhet használatba, hanem akkor is, ha olcsóbb, mint a gerinc fizikai link-jei. Például egy D-tôl F-be küldött csomag haladhat a cd, bc, virtuális link, af útvonalon, ha ez olcsóbb, mint a cd, ce, ef. Ez persze felettébb valószínûtlen, hisz a gerinc link-jei valószínûleg gyorsabbak, mint a területekéi, hisz a virtuális link fizikailag több link egymásutánja lehet.
Az OSPF összetett költséget használ, 4 összetevôvel. Ezek:
Ezek alapján több topológiai adatbázis építhetô fel, egy-egy a különbözô költségekhez és egy az „átlag" költséghez. A különbözô gráfokban számolt legrövidebb út adja rendre a leggyorsabb, legmegbízhatóbb, legolcsóbb és legkisebb késleltetésû útvonalat. Így lehetôség adódik az IP csomagokban levô TOS mezô figyelembevétele. Ha a csomagot valamelyik TOS bit beállításával adták fel, akkor a megfelelô gráfból kinyert legrövidebb (tehát legmegbízhatóbb, legkisebb késleltetésû, vagy legnagyobb sávszélességû) úton továbbítjuk, ha egyiket sem, akkor az „átlagos" költség alapján felépített gráfból származtatott úton. Ehhez azonban 5 topológiai adatbázis és 5 routing táblázat kell, ami drágítja a router-eket, így nyitott a lehetôség, hogy egy router csak a 0 TOS-t támogassa és csak egy (átlagos) topológiai adatbázist építsen fel.
Fontos, hogy a nem 0 TOS továbbítási útvonalon minden router támogassa a TOS-t, hiszen ha a fenti ábrában C-bôl B-be a nem 0 TOS (mondjuk a legnagyobb sávszélességû) útvonal a D-n keresztül vezet, D-bôl C-be pedig a 0 TOS útvonal C-n keresztül és D nem támogatja a TOS routing-ot, akkor C egy nagy sávszélességet igénylô csomagot D-nek ad fel, az viszont nem ismervén a sávszélességek alapján felépített topológiát, az átlagos költség alapján visszaküldi C-nek. A nem 0 TOS topológiai adatbázisokba tehát csak TOS router-ek rekordjait vehetjük fel. Ha az ily módon kapott topológia nem egybefüggô, mert túl kevés router támogatja a TOS-t, akkor a TOS alapján való route-olás csak az egybefüggô részeken belül lehetséges.
A területek közti összefoglaló információk terjesztéséhez hasonló módon terjeszthetünk külsô, az AS-en kívüli célpontokat is, melyekrôl egy EGP protokoll útján szerezhetünk tudomást. Az ilyen utak költségeként megadható egy második (type 2) költségfajta is, ami minden belsô használatú költségnél drágább. Ilyen esetekben az AS-en belüli továbbítás költsége nem számít, annál a router-nél fog távozni a csomag, amely a legolcsóbb type 2 költséget hirdeti, még ha az AS túlsó felén van is. Ez azért hasznos, mert az AS-ek közötti forgalom sokszor politikai megfontolásokat is követ, melyek fontosabbak az AS-en belüli költségeknél.
Összesen tehát négyféle információt terjeszt a Flooding protokoll:
A külsô utak kezelése opcionálisan implementálható OSPF képesség, azon router-ek, melyek nem tudnak külsô utakat kezelni, az ismeretlen hálózatok felé a default route-n továbbítják csomagjaikat. Azon területeknek, melyek csupán egy router-en át kapcsolódnak a gerinchez, nincs szüksége sem a külsô célpontok, sem a más területen levô célpontok összegzô információira, hiszen úgyis minden a területen kívülre küldött csomag azon az egy router-en át távozik. Az ilyen vak (stub) területeken éppen ezért csak a default route terjesztésére van szükség.
Az OSPF a link-eket az EIGRP-hez és a RIPv2-höz hasonlóan egy IP cím és egy maszk párosával definiálja, lehetôvé téve ezzel a változó hosszúságú subnet-ek használatát és a hálózatok aggregálását, errôl bôvebben a CIDR fejezetben olvashatunk.