
1990 Vancouver, IETF meeting: Megállapítják, hogy 1994 márciusra kimerül a B osztály. Több C osztályú cím kiosztása pedig a router táblázatok növekedést okozza. Erre megindultak a CIDR-erôfeszítések.
1992-ben IAB saját hatáskörben, a CIDR munkát félresöpörve megnevezte az IPv7-t és javasolta az IETF-nek, hogy „azonnal részletes és hivatalos tervet dolgozzon ki a CLNP-re épülô IPv7 kidolgozására". Ezt a merôben antidemokratikus javaslatot az IETF elvetette és tovább folytatta munkáját.
1993 Amsterdam IETF meeting: Az IPng munkacsoport megalakulása.
1993 szeptember: „Irányelvek az IPng-hez" [RFC1719] címen az IETF elnöke megjelenteti az IETF elképzelését. Megállapítja, hogy az IPng kidolgozása az IETF feladata, egyben létrehozza az IETF ideiglenes IPng területét.
1993 december, megjelenik egy felhívás [RFC1550] melyben az IETF javaslatokat kér az IPng-hez. Számos válasz jött rá a kábel TV, mobil távközlés, villamosenergia ipar, katonaság, részérôl az ATM, routing, security, nagyvállalati IP hálózatok, áttérési mechanizmusok és a piaci elfogadás témakörében. Az RFC1752 A függeléke tételes listát tartalmaz.
1994 december: Az IETF megfogalmazta az IPng jelöltek közötti választás kritériumát. [RFC1726] Eddigre 3 jelölt maradt:
A TUBA egyetlen elônye, hogy az IP közeledne az OSI megoldáshoz, minden másban csak problémát vetne fel. A CLNP nem rendelkezik például protokoll vagy folyam azonosítóval, source routing-ot használ, stb. Igazából a CLNP-t is módosítani kellene, de ekkor mindjárt nem lenne olyan kompatibilis, mint kellene. Ráadásul nem tudni pontosan, kinek van erre joga, lehet, hogy a CLNP módosítása az OSI hatásköre. A CATNIP igazán perspektivikus megoldás lenne, de a javaslat nem igazolta, hogy az IPX, IP, CLNP egyesítése valóban megoldható. A SIPP esetén a címtér kis volta miatt merültek fel aggodalmak, valamint az áttérés bonyolultsága miatt.
1994 május 31: Módosul a SIPP, immár 128 bit a címtér, az alsó 48 bitet a MAC címek foglalhatják el, így könnyebb az autokonfiguráció (ezt a TUBA-ból vették át).
1995 január: A módosított SIPP elfogadásra kerül [RFC1752], mint az egyetlen IPng javaslat.
1995 december: A javaslat az utolsó simítások után megjelenik [RFC1883]. Neve innentôl IPv6.
Látható, hogy az IPv6 az IPv4 szerves folytatása. Sem a TCP/UDP, sem a DNS, sem az egyéb alkalmazói protokollok nem változnak, csupán maga az IP, amely továbbra is megmarad megbízhatatlan szolgáltatást nyújtó datagram hálózatnak. Az egyetlen lényeges architektúrális változás az, hogy az ARP funkciót többé nem külön definiáljuk minden link-típushoz, hanem maga az IP tartalmazza Neighbour Discovery (ND) néven. Az egész protokollcsaládban általános lett a változó hosszúságú opciók beillesztésének lehetôsége, ezek mindig egy hossz, egy típus és egy adatmezôbôl állnak és minden esetben meghatározzák, hogy mit kell tenni a fel nem ismert opciókkal. Így egyértelmûvé válik, hogy egy késôbbi bôvítés esetén a régi berendezések hogyan viselkednek majd.
Az IP csomag fejléce meglehetôsen egyszerû, s bár a címek 16 byte-osak, mégis csupán dupla olyan hosszú, mint a régi IPv4 fejléc.
A csomag IP fejléce után más fejlécek is következhetnek, melyek az IPv4-ben még opciók voltak. Legelöl a minden hop által feldolgozandó fejlécek (Source Routing), majd a csak a végpontok által feldolgozandók (Hitelesítés, Titkosítás, Fragmentáció), végül pedig a felsôbb rétegek fejlécei (TCP, UDP, vagy az IP csomagba csomagolt IPX vagy másik IP csomag fejléce). Minden fejléc tartalmazza a következô fejléc típusát, kivéve az utolsó (a felsôbb rétegek fejlécei). Minden fejlécben benne van, hogy mit kell tennie annak a router-nek, aki nem ismeri fel (dobja el, továbbítsa, esetleg küldjön a feladónak ICMP üzenetet).
A fragmentáció csak a feladónak megengedett, tehát egy router nem darabolhatja a csomagot, ha a kimenô interface link-jén túl kicsi az MTU. Ilyenkor a csomagot el kell dobni és ICMP üzenetet kell vissza küldeni. Minden IPv6 link-nek minimum 576 byte hosszú MTU-val kell rendelkezni. Minden állomásnak támogatnia kell a Path MTU Discovery-t [RFC1191]. Ha a feladó állomás úgy találja, hogy a feladandó csomag túl nagy, dönthet a fragmentáció mellett, de ezt csak a feladó teheti meg, a közbeesô router-ek nem.
A csomag prioritása alapján dôl el, hogy ha egy router-ben csomagot kell eldobni, melyik vesszen. A 0-7 prioritások olyan forgalomfajtákat jelölnek, melyek késleltetést szenvedhetnek, ha torlódás van (például FTP, E-MAIL), 8-15 pedig olyanokat, melyek nem (interaktív, real-time forgalom). A két osztályba sorolt csomagok prioritása nem összehasonlítható.
A folyam azonosító alkalmas az ugyanattól a feladótól ugyanaddig a feladóig futó logikailag egybetartozó csomagok megjelölésére. Például egy TCP kapcsolat lehet egy folyam. Nem kötelezô azonban a használata, 0-ra állítva azt jelezhetjük, hogy a csomag nem tartozik egyetlen folyamhoz sem. [RFC1809]
Az ICMPv6 [RFC1885] egyenes átfordítása a korábbi ICMP-nek. Némileg bôvítették azonban, tartalmazza az IGMP-t [RFC1112] és a Path MTU-Discovery-t [RFC1191], melyekrôl késôbb még szólni fogunk. Kötelezô teljesen implementálni. A következô hibáknál érkezik vissza ICMP csomag: elérhetetlen célpont, túl nagy csomag, a csomag hop korlátját túlléptük, hibás csomag. Az ICMP azonban nem csupán hibák jelzésére használatos, hanem a hálózat managementjében is (echo kérelem, echo válasz, multicast csoport tagjainak lekérdezése és megválaszolása).
Az új IP használatakor a DNS-ben (Domain Name System) is kell változtatásokat végrehajtani, hogy az új, 128 bites IP címeket is lekérdezhessük; ezt egy új rekord bevezetésével oldották meg. Változtatásokat kell végrehajtani nemcsak a lekérdezô, de a válaszoló DNS komponensekben is, ezek részleteit az [RFC1886] tartalmazza.
Az új 128 bites címeket 8 darab 16 bites csoportra osztjuk, melyeket hexadecimális formában, egymástól kettôsponttal elválasztva írjuk, valahogy így:
FF7B:0:0:0:0:2C98:FFE8:0021.
A címben egy helyen szereplô hosszabb 0 szakaszokat helyettesíthetjük két kettôsponttal:
FF7B::2C98:FFE8:0021.
Az IPv6-ban unicast, multicast és anycast címek vannak. Az unicast cím egy állomás egy interface-ét jelöli, a multicast és anycast címek számos interface-t jelölnek (többnyire különbözô állomásokon), az elôbbire feladott csomag mindegyik, az utóbbira feladott pedig az egyik interface-re fog megérkezni. Az anycast címek szintaktikailag megkülönböztethetetlenek az unicast címektôl, a dolog úgy mûködik, hogy egyszerre több állomásnak is kiosztjuk ugyanazt a címet, természetesen errôl mindegyik állomásnak tudnia kell. Ezeket a címeket aztán a router-ek terjeszteni is fogják. Minthogy ezek a címek jó eséllyel aggregálhatatlanok lesznek, a globális anycast egyenlôre problémásnak hat. A multicast címek felsô 8 bitje 1. A következô 4 bit 4 flag-et tartalmaz, melyekbôl egyenlôre csak egy definiált, az azt mondja meg, hogy a cím egy általános (well-known) vagy csak ideiglenes (tranziens) multicast csoport-e. A következô 4 bit pedig a csoport hatókörét jelzi (állomás, link, telephely, szervezet, globális).
A következô elôre definiált multicast címek léteznek:
A 0::0, vagy csak :: cím jelzi cím hiányát.
A ::1 cím a loopback cím, az erre feladott csomag nem hagyhatja el az állomást, visszakapja a feladó.
Az olyan állomások, melyek IPv6 állomások, de kénytelenek az IPv4 router-hálózaton keresztül információt átküldeni, a ::0:152.66.77.1 formátumú címeket kaphatják, ahol az utolsó 32 bitet a régi konvenció szerint decimálisan írjuk. Azon állomások címét, melyek nem ismerik az IPv6-ot, a ::FFFF:152.66.77.1 jelöléssel adhatják át egymásnak az IPv6 állomások.
A cím felsô bitjei itt is a cím funkcióját
azonosítják, de nem címosztályokat jelölnek,
a címtér felosztására csak funkcionális
okokból került sor.
|
|
|
|
|
|
0000 0000 | 3.9 ‰ |
|
|
0000 001 | 7.8 ‰ |
|
|
0000 010 | 7.8 ‰ |
|
|
010 | 125 ‰ |
|
|
100 | 125 ‰ |
|
|
1111 1110 10 | 1 ‰ |
|
|
1111 1110 11 | 1 ‰ |
|
|
1111 1111 | 3.9 ‰ |
|
|
minden egyéb | 725 ‰ |
A link-en lokális címek (röviden link-local címek) olyan címek, melyek csupán az adott link-en egyediek és éppen emiatt csak a link-en való kommunikációra használhatóak. A router-ek feladata, hogy ilyen feladó címmel ellátott csomagokat ne továbbítsanak a link-en kívülre. A telephelyen lokális címek (site-local) címek pedig értelemszerûen csak a telephelyen belül használatosak. Egy állomásnak, sôt akár egy interface-nek így több címe lehet, ezek közül néhány link-local, néhány site-local néhány pedig globális lehet. Minden állomás kötelezô felismerni saját magát a következô címekben:
A címzési architektúra részleteit az [RFC1884] tartalmazza.
Mint a fentiekbôl is látszik az IPv6 némileg összetettebb, mint az IPv4. Ám mindez még semmi ahhoz képest, amit a következô fejezetben olvashatunk.
Mind már korábban említettük az IPv6 nem használja az ARP-t, a szomszédos állomások felkutatása IP szinten folyik. Mûködését elôször broadcast link-ek esetében mutatjuk be, majd rátérünk az egyéb link-ekre.
Az IPv6-ban minden router periodikusan hirdetményeket (Router Advertisement) postáz a minden-állomás címre, melyet természetesen az alatta lévô adatkapcsolati szint broadcast üzenetként fog elküldeni. Ebben a router közzéteszi saját MAC címét, a link-en használatos prefixeket és egyéb információkat, mint például a link MTU vagy az, hogy a kívülre küldött csomagokban mekkora hop-korlát használata javasolt.
A router hirdetmények számos kérdést megoldanak. Egyrészt minden állomás összeállíthatja a link-en lévô router-ek listáját, ezek felderítésére tehát a továbbiakban nincs szükség, mint az IPv4-ben. A router-ek MAC címét sem kell ARP-vel megtudakolni, ráadásul olyan paraméterek, mint az MTU egy központi helyrôl konfigurálhatóak. Ezenfelül az állomások maguk állíthatják elô valamely kitüntetett prefix segítségével saját címüket. Azt is központi helyrôl közölhetjük az állomással, hogy ne állítson elô így címet, hanem keresse a DHCP servert. Errôl bôvebben a következô fejezetben olvashatunk.
Ha egy állomás bekapcsolódik nem kell megvárnia a router-ek periodikus hirdetményeit, egy a minden-router címre küldött felszólítással (Router Solicitation) kiválthatja azok soron kívüli elküldését is. A hirdetményekbôl az állomás elôállíthatja a link-en használatos prefixek listáját is, így egy adott csomagról a cím alapján könnyen el tudja majd dönteni, hogy az adott link-re szól vagy egy router-nek kell elküldeni. Ettôl függetlenül, ha egy állomás címe nem illeszkedik egyik prefixre sem, az még nem feltétlen jelenti, hogy nincs az adott link-en, hiszen lehetnek rögzített címû állomások, melyek prefixe eltér minden más ezen a link-en használatos prefixtôl. Ebben az esetben az állomás a csomagot egy router-nek küldi, aki továbbítja is a célpont felé, de egyúttal egy átirányító (Redirect) üzenetben közli az állomással hogy a kérdéses IP cím gazdája a link-en van és megmondja annak MAC címét is.
Az címfeloldás a következôképpen zajlik. A kérdezô állomás a kérdéses IP címbôl kiszámolja a hozzá tartozó megszólított-állomás (Solicited-node) multicast címet. Ez úgy történik, hogy a kérdéses IP cím utolsó 32 bitjét az FF02::1/96 prefixhez illesztjük. Erre a címre aztán felad egy felhívást (Neighbour Solicitation), melyben közli saját IP és MAC címét, valamint a keresett IP címet. A megszólított állomás, ha a link-en van, megkapja ezt a felszólítást, hiszen ô figyeli a saját IP címéhez tartozó megszólított-állomás multicast címet. A kérdésre egy a feladóhoz intézett közvetlen, unicast csomaggal válaszol (Neighbour Advertisement).
A megszólított-állomás multicast csoportok használata arra jó, hogy azon állomásoknak, akikhez biztosan nem szól a megszólítás (címük utolsó 32 bitje más), nem kell IP szinten foglalkozni a megszólítással. ARP használata esetén erre minden állomásnak szüksége volt, legalább annyira, hogy észrevegye, hogy nem az ô címét kérik. Ez az IP processzben fölösleges megszakítások érkezésével járt, amit az ND megspórol.
A szomszédokhoz intézett felhívás arra is jó, hogy egy állomás elérhetetlenségét leellenôrizzük; ha valamilyen okból (például TCP timeout) gyanús lesz, hogy a partnerünk az adott link-en már nem él, egyszerûen a fenti módon megszólítjuk, s ha nem válaszol, akkor gyanakodhatunk csak igazán.
Ha egy állomásnak menet közben megváltozik a MAC címe, akkor elég, ha néhányszor kérés nélkül is fölad a minden-állomás multicast címre egy hirdetményt (Neighbour Advertisement), melyben új MAC címét és IP címét reklámozza. Ez természetesen nem megbízható módja az értesítésnek, hisz a csomagok célbajutását senki sem garantálja, de aki meghallja, az hamarabb értesül a változásról. Aki nem, az elôször gyanakszik, majd felszólítja a megszólított-állomás multicast címen, mire ô már új MAC címével válaszol és ez addig zajlik, míg végre a válasza el nem jut a kérdezôig.
Ha egy állomás több interface-szel rendelkezik az adott link-en, akkor a különbözô kérdezôknek más-más MAC címekkel válaszolva elérheti, hogy az állomások a neki szóló csomagokat interface-ei között egyenletesen elosztva továbbítsák neki. Ez különösen router-ek esetén lehet hasznos.
Az olyan állomások helyett, melyek címe illeszkedik adott link prefixeinek egyikére, de mégsem tartózkodnak az adott link-en, egy router vállalhatja el a szomszéd felhívásokra való válaszadást, így a távollévô állomásnak szánt csomagokat ô kapja meg és ô továbbíthatja. Ez például mobil állomások esetén hasznos (lásd késôbb).
Pont-pont link-ek tekinthetôek úgy, mint egy két állomásos broadcast link, az ND minden változtatás nélkül mûködik. Nagyobb a probléma a nem broadcast jellegû (NBMA) link-ek esetén. Itt az IP szint feladata, hogy a minden-router, a minden-állomás és a megszólított-állomás multicast csoportokra megfelelôen juttassa el a csomagokat. A szomszédok megszólítása pedig közvetlen nekik szánt unicast csomagokkal mehet. Ha a megszólítás címfeloldás céljával történik, azaz még nem ismerjük a célpont MAC címét, akkor nyugodtan elküldhetjük a router-nek az elsô csomagot, a pedig majd egy átirányító (Redirect) üzenetben közli velünk a MAC címet. Mindehhez az állomásokban csupán a router-ek MAC címét kell konfigurálni, ezekre a címekre küldött router felszólításokkal kiválthatjuk a router-ek válaszát (Router Advertisement) és egyben jelezhetjük nekik, hogy mostantól mi is a link-en vagyunk.
NBMA link-ek fölött így szükséges, hogy az IP multicast mûködjön, legalább a minden-router, minden-állomás és megszólított-állomás multicast címekre. Az, hogy ez hogyan érhetô el, jelenleg nem tiszta, de az IPv6-over-ATM részben még visszatérünk a kérdésre.
Bár a fenti mechanizmus talán bonyolultnak tûnik, különösen a sok támogatott cím és funkció miatt, ha jobban belegondolunk, mindezen funkciókat eddig is megvalósították az IPv4 hálózatok (ARP, ICMP Redirect, ICMP router discovery, DHCP MTU configuration, stb.), csupán sokkal rendezetlenebb és toldozgatott-foldozgatott módon. Itt most mindez egységesen és letisztulva jelenik meg. Részleteket a [26] tartalmaz.
Az IPv6 alapvetôen kétféle autokonfigurációt definiált. Az egyik szigorúbb és precízebb, a konfigurációs információkat itt egy server szolgáltatja, alapját a DHCP képezi (stateful autoconfiguration). A másik némileg egyszerûbb, az állomások önmagukban is képesek lebonyolítani, az ND módszereit használja és implementálása erôsen javasolt (stateless autoconfiguration). [25]
Ez utóbbi a következôképpen zajlik. Minden állomás eleve rendelkezik egy olyan azonosítóval, ami a link-en egyedi módon azonosítja: ez a MAC címe. Az autokonfiguráció céljaira használhatunk más azonosítót, de ez a legkézenfekvôbb. Ebbôl az azonosítóból és az FE80:0::/10 (link-local) prefixbôl minden állomás elôállíthatja saját link-local címét, aminek segítségével legalább a link-en kommunikálhat. Ha a MAC cím hosszabb, mint a prefix mellett rendelkezésre álló 118 bit (például az ATM NSAP címek 160 bit hosszúak), akkor annak végefelôl vehetünk el 118 bitet, az ilyen címeknek általában a vége azonosítja az állomást, az eleje sokkal inkább a route-oláshoz kell. A kérdés azonban ennyire nem egyszerû, hiszen jó lenne olyan azonosítót választani, ami állandó és ez például ATM címrôl nem mindig mondható el. A kérdés mindenesetre még nyitott. [27]
A kapott link-local címet azonban még nem használhatjuk, hiszen lehet, hogy más állomás is pont ugyanerre a címre jutott; a cím még kérdéses (tentative). A kérdéses címekre kapott csomagokat az állomás figyelmen kívül hagyja, kivéve a szomszéd felszólításokat (Neighbour Solicitation) és a rájuk érkezô válaszokat, mert ezek segítségével ellenôrizzük a cím egyediségét.
A link-local cím birtokában feladunk egy szomszéd felszólítást a link-local címbôl számított megszólított-állomás multicast címre. Ha senki sem válaszol (meghatározott idôn belül), akkor úgy vehetjük, hogy a címet csak mi használjuk. Ez a módszer nem atombiztos, hiszen ha az ellenôrzés alatt a link két részre szakadt, akkor az egyesülés után vidáman lehet két azonos címû állomás, de ezt más módszerrel se tudná az adott állomás önmagában felderíteni.
Link-local címünk véglegesítése után, a router-ek által kibocsájtott hirdetményekre (Router Advertisement) várunk (esetleg a minden router csoportra elküldött felszólítással ezt megsürgetjük). A kapott hirdetménybôl eldöntjük, hogy végre kell-e hajtanunk önálló autokonfigurációt vagy sem. Ha igen, az erre a célra megjelölt prefix(ek)bôl és a korábban használt azonosítóból elôállítjuk további címeinket. Ezek egyediségét már nem annyira fontos ellenôrizni, hiszen az egyediség fôként a MAC címbôl (vagy máshonnan) nyert azonosító egyediségén múlik, efelôl pedig a link-local cím generálásánál már meggyôzôdhettünk. Elôfordulhat, hogy a router hirdetményében mind önálló, mind DHCP server segítségével lezajló autokonfiguráicóra utasítja az állomást, ez nem probléma, ha több címünk van, csak jobb.
Természetesen a DHCP-t is kissé módosítani kellett. [24] A protokoll fô gondolata ugyanaz maradt, de most már a server vissza is vonhat IP címeket az állomástól (Release) és kérheti az állomástól, hogy indítson új konfigurációs folyamatot (kérés-válasz), mert új konfigurációs információ áll rendelkezésre. A protokoll ezenfelül javaslatot tesz a DNS-sel való együttmûködésre is.
Egy állomás több címe közül bizonyos címek élettartama hosszabb lehet, mint másoké. Ez elsôsorban átszámozásoknál merül fel, ahol a régi és az új cím még egyaránt érvényben van, de a régi használata ellenjavallt. Ilyenkor az IP szintnek rendelkeznie kell valamilyen mechanizmussal arra, hogy a felsôbb rétegek felé közölje, hogy melyik cím milyen célra használatos és használata mennyire kívánatos. Minthogy jelenleg sem a TCP sem az UDP nem képes menet közben címváltozást elviselni a kontextus megszakadása nélkül, ilyen esetekben a leghosszabb élettartamú címet érdemes használni. Ezen a módon az átszámozások a DHCP serverben központosítva, félig automatikusan zajolhatnak le.
Azzal pedig, hogy egy állomásnak több címe lehet, megoldódott az a probléma is, hogy valaki több szolgáltatónál fizet elô és akár napszaktól függôen váltogatni kívánja szolgáltatóját. Ha a szervezet minden állomása mind a két szolgáltató prefixébôl elôállít magának egy címet, akkor mindkét szolgáltatónak csak saját prefixét kell kifelé terjesztenie, ami könnyen aggregálható, és bármely címre küldött csomag üzembiztosan eltalál a címzetthez. A napszak végén, szolgáltatóváltáskor a kimenô csomagokat a router-ek a másik szolgáltató felé irányítják (megváltoznak a BGP preferenciák), az állomások pedig annak a szolgáltatónak prefixébôl képzett címüket írják a csomagok feladó cím mezôjébe, így a válasz is onnan fog érkezni. Azok a TCP kapcsolatok csomagjaiban, melyek nyitva maradtak, nem változtathatunk a feladó címen, különben elvész a másik oldalon a kontextus, de ez nem baj, legfeljebb forgalmuk (legalábbis a beérkezô) a régi szolgáltató felôl fog érkezni. Új TCP kapcsolat azonban már az új szolgáltató prefixébôl kapott feladó-címmel épül ki és így a visszatérô forgalom is onnan érkezik majd. Az állomásokban a változást a DHCP server eredményezheti, az állomások újrakonfigurálásával, ha csupán a címek preferenciáját változtatja meg.
Az elôbbi fejezetekben leírt ND protokoll nagyon szép, roppant hasznos és áttekinthetô, egyetlen problémája, hogy feltételezi az adatkapcsolati szinten mûködô multicast képességet. A probléma elintézésének legegyszerûbb módja, hogy úgy tekintünk az IP és az ATM közötti IPv6-over-ATM rétegre, mint egy fekete dobozra, ami varázslatos módon támogatja a multicast-ot.
Ezt megoldhatjuk a korábban ismertetett MARS (Multicast Address Resolution Server) segítségével, ám ez a megoldás azt jelentené, hogy egy IP alatti réteg multicast címfeloldási funkcióit (a MARS-ot) használná fel egy másik címfeloldási funkció (az ND). A megoldás emellett nem támogatná a subnet-eken kívüli címfeloldást és közvetlen VC létesítését, mint az NHRP. [27]
Erre a kérdésre valami sokkal jobb megoldás is adható.
Az eddigiekben fel kellett, hogy tûnjön nekünk, hogy az IPv6 tárgyalása közben nem szerepelt az IPv4-ben oly fontos subnet fogalma. Az IPv4-ben a subnet olyan része a hálózatnak, ahol:
A link pedig olyan része a hálózatnak, ahol bármely két állomás képes közvetlen kapcsolatot teremteni egymással.
Nyilvánvalóan egy subnet-nek teljes egészében egy link-en kell lennie az 1. követelmény miatt, viszont egy link-en több subnet is létrehozható. Ez azonban ritkán éri meg, hiszen mindössze azt érjük el vele, hogy bár a link képes lenne a közvetlen összeköttetésre, mégis egy router továbbítja a csomagot. Pontosan ez történik a klasszikus IP-over-ATM-ben.
Nagy általánosságban nincs tehát szükség a subnet és a link fogalmának elkülönítésére, ez csak rontja a teljesítményt. Ez azonban számos problémát vet fel. Tekintsük például az ATM link-et. Várható, hogy egy idô után jókora méretû ATM hálózatok alakulnak majd ki magán ATM hálózatoknak a nyilvános ATM szolgáltatáson keresztül történô összekapcsolása útján. Ez IP szempontból egy link, mégsem kívánatos, hogy bármely két állomás elérhesse egymást ATM szinten, hisz a vállalati hálózatokat IP tûzfallal szokás védeni. Emellett számítógép legyen a talpán aki ilyen nagyméretû hálózatban mûködtetni tudja az ND-t. Más link-ek esetén (például a hagyományos LAN-ok) e két probléma nem igazán merül fel.
Definiálni kell tehát az ATM link fogalmát. Nyilvánvaló hogy egy ATM hálózat nem lehet egy link. Azt mondjuk tehát, hogy egy ATM link az ATM hálózat egy elkülönített része, melyben mûködik az ND. (Bár a definíció így körkörös.)
[28] részletesen leírja az ND ATM fölötti mûködését (legalábbis felveti egy lehetséges implementációját), ez a következôképp zajlik.
Egy ATM logikai link-et (LL) egy Neighbour Discovery Server-hez (NDS) tartozó állomások alkotnak. Az LL állomásai fizikailag bárhol elhelyezkedhetnek az ATM hálózatban, hiszen teljes az ATM konnektivitás, ezért logikai a link. Az NDS nem IP szintû berendezés, nincs IP címe és nem vesz IP csomagokat, feladata az ND lebonyolítása a logikai link-en.
Ahhoz, hogy az LL-ek között is mûködhessen az ND, definiálunk egy a logikai link-ek NDS-ei fölött álló, az egész telephelyt kiszolgáló NDS-t. Az elôbbieket NDS(LL)-nek, míg ezt NDS(T)-nek hívjuk. Hasonlóképpen létezik egy a telephelyek fölött álló NDS(Gy) is, a gyökér.
Egy állomás bekapcsolásakor ismerje kell az NDS(LL) címét. Erre a címre létrehoz egy pont-pont VC-t és bejelentkezik. Erre az NDS(LL) felveszi az LL összes állomásához futó pont-multipont kapcsolatához. Ezek után az NDS(LL) feladata, hogy az ND-hez szükséges multicast forgalmat szétterítse az LL-ben. Aki tehát valamelyik, az ND-vel kapcsolatos multicast címre adni akar, csomagját az NDS(LL)-nek címzi, az pedig szétküldi mindenkinek. Az állomások feladata, hogy a nem nekik szóló csomagokat eldobják (például a minden-router címre érkezô csomagokat csak a router-ek tartják meg).
A fenti módon lehetséges olyan szomszédokat is megszólítani, akik nem a mi LL-ünkön vannak. Ezt úgy tehetjük, hogy a kérdéses állomás IP címébôl kapott megszólított-állomás multicast címre adunk fel csomagot, de nem link hatókörrel, hanem például telephely hatókörrel. Természetesen ezt a csomagot is az NDS(LL)-nek küldjük, az azonban nem csupán a link-en belül osztja szét, hanem postázza az NDS(T)-nek is, akinek pont-multipont kapcsolata van minden NDS(LL)-hez és ezen szétteríti a felhívást minden NDS(LL) között, akik pedig a saját LL-ükben terjesztik. A felhívás így minden a telephelyen lévô állomáshoz eljut, a megszólított állomás pedig közvetlen VC-t létesít a kérdezôhöz és válaszol.
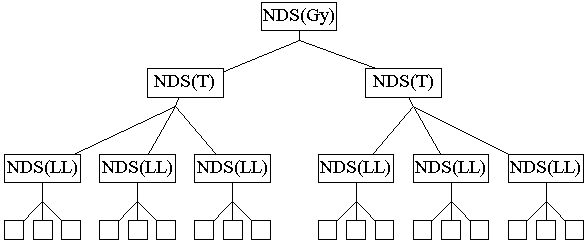
A dolog azonban nem ilyen egyszerû, nagy ATM hálózatokban ugyanis három hierarchia szint lehetséges, hogy nem lesz elegendô. Éppen ezért a három logikai szintet megtartva fizikailag több szintet is létrehozhatunk. Tehát az NDS(LL) alatt lehet még egy szint, ezek az NDS(LL-1) serverek semmit nem csinálnak, csak buta módon továbbadják az alulról érkezô csomagokat fölfelé és a fölülrôl érkezô csomagokat pedig szétosztják lefelé, valamint fogadják a regisztrációkat. Hasonlóképpen egy vagy több szint lehet még az NDS(LL) és NDS(T) valamint az NDS(T) és NDS(Gy) között is, s így egy NDS-nek kevesebb állomást kell kiszolgálnia.
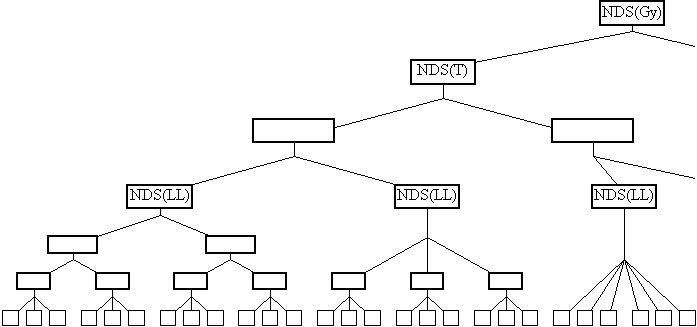
Az NDS-fa az ND azon üzeneteit mozgatja csak, melyek multicast címekre szólnak (Router Solicitation, Router Advertisement, Neighbour Solicitation), a többit (Neighbour Advertisement, Redirect) az ND-ben leírtak szerint unicast csomagokban, tehát közvetlen VC kiépítésével kell elküldeni. Az NDS-fa alkalmas lenne más multicast forgalom lebonyolítására is, de feladata nem az IP multicast megoldása, csupán az ND implementálása. Az NDS-fa egyéb célokra való felhasználása szabványosításának jogát az IETF fenntartotta magának.
Annak érdekében, hogy például egy állomás megszólítása csomag ne a teljes fában terjedjen szét, az NDS-ek megjegyezhetik, hogy alattuk milyen prefixû állomások találhatóak és azokat a csomagokat, melyek csupán egy alattuk levô NDS területéhez szólnak, csak annak az NDS-nek küldik el a pont-pont kapcsolaton, nem pedig szétterítik az összes alattuk levônek a pont-multipont-on. Ezzel jelentôs forgalmat takaríthatunk meg és az állomások zömét nem zavarjuk feleslegesen. Ahhoz, hogy egy NDS ismerje az alatta levô prefixeket, a router hirdetményeket felfelé is továbbítani kell a fában, mert azokban vannak a használatos prefixek. Ezt is teszi minden NDS.
Az UNI 4.0 lehetôségeivel számos egyszerüsítést érhetünk el. Az anycast címeknek itt szintén van hatókörük, mint az IP multicast címeknek, tehát itt is behatárolható, hogy egy anycast hívás milyen széles körben keres. Kétféle hatókör definíció látott napvilágot, az egyik a PNNI hierarchiára épül, a másik attól független és 16 szintet definiál, kissé másokat, mint az IP 16 szintje, de hasonlóan. Az ND céljaira ez az utóbbi alkalmasabb, mert a szintek száma állandó és nem függ a PNNI hierarchiától.
Ezen szintek felhasználásával történhet az NDS-fa felépítése, minden szinten lehet egy NDS szint is, az NDS(LL), NDS(T) és NDS(Gy) szintek bármelyikek lehetnek a 16-on belül (persze az NDS(Gy) legyen az NDS(T) fölött, az pedig az NDS(LL) fölött). Ez azt a kellemes tulajdonságot vonja maga után, hogy ha mind a 16 szintre definiálunk egy jól ismert ATM anycast címet nevezzük C(n)-nek, mely az adott szint NDS serveréhez vezet, akkor az állomásokba csak ezt a 16 jól ismert címet kell beleégetni. Az állomások bekapcsoláskor felhívják a legalsó szint anycast címét, az C(1)-t és ha ott létezik NDS server, akkor már meg is történhet a regisztráció, ha nem, vagy az adott NDS(1) éppen elromlott, akkor a C(2) anycast címen keresnek NDS-t, majd egyre följebb mindaddig, amíg nem találnak. Így egy szinten több, redundáns NDS(n) is lehet, ha egy kiesik, az anycast hívás megtalálja a másikat, így az átveheti azokat az állomásokat, akik az elsô NDS lehalása miatt újra próbálkoznak.
A folyamat során mindössze a logikai szinteket kell betartani, tehát például az NDS(LL) feletti NDS-hez állomás nem csatlakozhat. Az NDS(LL), NDS(T) és NDS(Gy) kitüntetett szerepe miatt ezek az állomások nem kettôzhetôk meg és meghibásodásuk az adott terület kiesését jelenti. Ez a javaslat egyik gyenge pontja.
Igazából az egész NDS fa autokonfigurálható UNI 4.0 esetén. Egy n. szintû NDS, azaz NDS(n), bekapcsolásakor bejelentkezik az ATM hálózatnál és feliratkozik a C(n) címre, hogy az alulról jövô hívásokat fogadhassa. Ezután felhívja a C(n+1) címet és keresi a fölöttes NDS-ét. Ha ott nem talál, akkor egyre feljebb keres. Ha egyáltalán nem talál felettes NDS-t akkor megállapítja, hogy ô az NDS(Gy). Ha talál, akkor közli vele saját szintjének számát. Ha ez a szint túl alacsony (például egy NDS(LL) alatti NDS csatlakozni kíván az NDS(T)-hez), akkor a kapcsolat megszakad; ez egy kulcsfonotsságú NDS (példánkban az NDS(LL)) hiányát jelzi.
Ha egy felettes NDS úgy tapasztalja, hogy alulról több szintû NDS is csatlakozott hozzá, például egy NDS(8)-hoz egy NDS(5) és NDS(6) is kapcsolódott, akkor a legmagasabb szintet kivéve minddel megszakítja az összeköttetést, esetünkben az NDS(5)-ökkel. Ekkor azok újra elölrôl próbálkoznak a kapcsolatteremtéssel, elôször a C(6) címen, ahol rá is találnak a frissen bekapcsolt NDS(6)-ra és a fa újra helyreáll.
Az egész autokonfiguráció hátárnya, hogy ATM topológiaváltozás esetén az állomások más LL-be kerülhetnek, hisz a „legközelebbi" NDS másik LL-ben lehet. Ha nekünk a kapott LL nem felel meg, a végleges címünk duplázások elleni leellenôrzése elôtt kérhetjük az NDS-tôl a prefixünknek megfelelô LL-be való átirányításunkat. A kérelem felcsorog az NDS(LL)-ig, az leellenôrzi, hogy nincs-e mégiscsak ebben az LL-ben az adott prefix és ha nem, akkor felfelé adja a csomagot, mindaddig, amíg valamelyik NDS rá nem ismer. Ekkor leadja a kérelmet a megfelelô terület valamelyik legalsó NDS-éig, aki VC-t hoz létre az átirányítást kérô állomáshoz, aki ezen regisztrálja magát.
Ezzel a megoldással igen nagy ATM link-ek hozhatók létre, egy ATM hálózatban lehet több fa is, ezek között csak router-eken át lehet kommunikálni. A fák elrendezése nem függ a fizikai helytôl (legalábbis, ha nem használunk autokonfigurációt). Az IP szint számára észrevehetetlen módon mûködik az ND, minden multicast csomagot fel tudunk adni és meg is kapunk, az egyetlen különbség, hogy az adatcsomagok elküldéséhez ki kell építeni egy VC-t, ami miatt viszont a QOS-t megadhatjuk.
A javaslat korántsem teljes vagy precíz, ám jó képet alkothatunk magunknak arról, mire képes két ilyen modern hálózati technológia együttmûködése, milyen széles körû lehet az autokonfiguráció és mennyi elônnyel jár, ha figyelünk rá.