Alapvetõ fįjlkezelõ parancsok
Ebben a pontban azokat az alapvetõ parancsokat tekintjük įt, amelyekkel įllomįnyokat tudunk létrehozni, megtekinteni, mįsolni, és egyéb mūveleteket végrehajtani rajtuk.
Egy įllomįny létrehozįsįra sok - kezdõk szįmįra talįn tślsįgosan is sok - megoldįs létezik. Létrehozhatjuk egy szövegszerkeszõvel (példįul ed, vi), kétségkķvül ez a leggyakoribb és legkézenfekvõbb megoldįs. Most viszont néhįny "trükkösebb" megoldįssal kezdünk, melyek egyben segķtenek néhįny alapvetõ Unix jellemvonįs megismertetésében is. Mindegyik példįnkban a "Szép idõnk van ma" szöveget próbįljuk meg egy įllomįnyba beķrni.
Elsõ megoldįsunk az echo parancsra épül. Az echo a DOS alatt megszokott módon mūködik (az eltérésekrõl majd lesz szó): a parancssorban argumentumként megadott karaktereket tükrözi vissza, alapértelmezés szerint a képernyõre. A fįjlba ķrandó szöveget ķgy az echo paranccsal a képernyõre mįr kilistįzhatjuk. Félsiker... A teljes sikerhez az įtirįnyķtįs mechanizmusa segķthet minket. Lehetõség van ugyanis arra, hogy tetszõleges Unix parancs bemenetét vagy kimenetét įtirįnyķtsuk mįshova, példįul egy fįjlba. Esetünkben a >newfile1 megadįssal a kimenetet, a képernyõ helyett a newfile1 nevū fįjlba. És ķme, készen is vagyunk:
$ echo Szep idonk van ma >newfile1
RETURN$
(Ne feledkezzünk meg az egyes sorok végén a kocsi-vissza karakter (RETURN vagy ENTER) leütésérõl; a tovįbbiakban ezt nem jelöljük.)
Következõ próbįlkozįsunk a hamarosan részletesebben is ismertetendõ cat parancsot hasznįlja fel. A cat parancs egy vagy több, argumentumként megnevezett fįjl tartalmįt listįzza ki a képernyõre (példįul cat prog1.c prog2.c). Elsõ rįnézésre ez nem sokat segķt rajtunk, hiszen mi nem egy meglévõ fįjlt akarunk listįzni, hanem épp ellenkezõleg, egy még nem létezõ fįjlt akarunk ķrni - pestiesen szólva "a többi stimmel...".
Minden "jól nevelt" Unix programra igaz azonban, hogy ha nem nevezünk meg įllomįnyt, amit be kell olvasnia és fel kell dolgoznia, akkor alapértelmezés szerint (szįmķtįstechnikai zsargonnal élve, default értelmezés szerint) a billentyūzetrõl (standard input) vįrja a feldolgozandó adatokat. Hasonlóképpen, explicit kimeneti įllomįnynév hiįnyįban a programok a képernyõre (standard output) ķrnak. Az e konvenció szerint viselkedõ programokat szemléletesen szūrõknek (filter) nevezik, a késõbbiekben még sok szó esik róluk. Ha tehįt a cat parancsot bemeneti fįjlnév nélkül hķvjuk meg, akkor az įltalunk kķvįnt módon, a billentyūzetrõl bevitt szöveget listįzza ki, a kimenetet pedig a mįr lįtott módon irįnyķthatjuk įt a kķvįnt fįjlba:
$ cat > newfile2
RETURNSzep idonk van ma
RETURNCTRL-D
$
(A RETURN karakter hasznįlatįn kķvül most vigyįzzunk arra is, hogy a kķvįnt szöveg begépelése utįn a CTRL-D karaktert is leüssük, hiszen ez jelzi a parancsértelmezõnek, hogy nincs több bemeneti adat.)
A fenti két trükk, a szūrési konvenciók létezése és az įtirįnyķtįs hihetetlenül rugalmassį teszi a Unixot.
Végül utoljįra egy szövegszerkesztõvel is létrehozunk egy fįjlt:
$ ed newfile3
?newfile3
a
szep idonk van ma
.
w
18
q
$
Az ed editorról külön fejezet szól a könyvben, mostani példįnk tényleg csak egy rövid szemléltetõ volt. Az ed-nek megadjuk a létrehozandó fįjl nevét, a parancs begépelése (és az itt mįr külön nem jelölt RETURN leütése utįn) elindul az editor, és śgynevezett parancsmódban vįrja a parancsokat. (A kérdõjeles fįjlnév azt jelzi, hogy ilyen nevū įllomįny eddig nem létezett - mįr létezõ fįjl esetén a fįjl méretét ķrja ki, karakterekben szįmolva.) Az įltalunk kiadott parancs az a (append), ennek hatįsįra az ed az śgynevezett beviteli módba kerül, s az ebbõl való kilépésig mindent, amit gépelünk, vįltozatlan formįban az įllomįnyba ķrja. A beviteli módból śgy lehet kilépni, hogy egy sor elején egy önmagįban įlló . (pont) karaktert ķrunk be (ez utįn is kocsi-visszįt kell ütni!). Ennek hatįsįra visszakerülünk parancsmódba; ekkor kiadtuk a w (write) parancsot, ez lemezre ķrja, tehįt elmenti a fįjl eddig ideiglenes tartalmįt (a képernyõre kiķrja az elmentett fįjl aktuįlis hosszįt), végül a q (quit) paranccsal kilépünk az editorból.
Fįjlok megtekintése: a cat parancs
A fįjlok megtekintésére, pontosabban a képernyõn történõ megjelenķtésre a cat parancs szolgįl. (A név onnan szįrmazik, hogy ha több fįjlnevet adunk meg, akkor ezeket a fįjlokat egymįsutįn folyamatosan (concatenated) jelenķti meg... - ennyit a parancsnevek memorizįlható jelentésérõl...)
A cat parancs a paraméterként megnevezett fįjlokat, ennek hiįnyįban pedig a standard inputot, azaz a billentyūzetrõl, pipe-ból (csõbõl) érkezõ adatokat listįzza ki, folyamatosan, tördelés nélkül. Ez azt jelenti, hogy ha a megjelenķtendõ įllomįny nagyobb, mint egy képernyõoldal, akkor a szöveg kiszalad a képernyõrõl, s csak a listįzįs-felfüggesztõ, illetve śjraindķtó gombbal lehet szabįlyozni a megjelenķtést. (E két funkciónak rendszerint a CTRL-S, illetve a CTRL-Q billentyū felel meg.) A cat parancs ezen hiįnyossįgainak kiküszöbölésére szolgįl a pg és a more, róluk részletesebben a minimanuįlban esik szó. Szįmunkra jelenleg legfontosabb parancsuk pg esetében a RETURN, more esetében a szóköz billentyū; ezek hatįsįra egy képernyõoldalnyit lehet elõrelapozni.
Fįjlok įtnevezése: a mv parancs
Gyakran szükséges egy fįjlt mįshova helyezni az įllomįnyrendszerben, erre a UNIX alatt a mv (move) parancsot hasznįlhatjuk. A legegyszerūbb esetben egyetlen fįjlt helyezünk įt, példįul a mįr létezõ newfile1 įllomįnyunkat file1 néven akarjuk a tovįbbiakban elérni:
$ mv newfile1 file1
$ ls -l newfile file1
newfile not found
-rw-rw-rw- 1 demo guest 18 Aug 23 20:42 file1
$
A fenti példįban a mv parancs két paramétert fogad, s az elsõnek megadott fįjlt a mįsodikként megadott névre nevezi įt. Ha a "céltįrgy" is közönséges fįjl, akkor egyszerū įtnevezés történik, az eddig newfile névre hallgató įllomįnyt ezentśl file1 néven érhetjük el. (Ha file1 elõzõleg nem létezett, akkor a mv parancs automatikusan létrehozza, ha mįr létezett, felülķrja.)
Ha a céltįrgy katalógus, akkor a mv parancs mįsképpen mūködik: az elsõ paraméterben megnevezett fįjlt a régi néven, a céltįrgyként megadott katalógus alį helyezi. Ez esetben lehetõség van arra is, hogy kettõnél több paramétert adjunk meg a mv parancsnak: ilyenkor az utolsó argumentumot tekinti a rendszer az įtnevezés célkatalógusįnak, s a többi argumentumban megnevezett fįjlokat oda helyezi įt. Ha példįul kiadjuk a mv newfile2 newfile3 newdir parancsot (ne felejtsük el, hogy a newdir katalógust elõzõleg mįr létrehoztuk), akkor newfile2 és newfile3 egyarįnt bekerül a newdir katalógusba, vįltozatlan néven:
$ mv newfile2 newfile3 newdir
$ ls -lR
total 362
-rw-rw-rw- 1 demo guest 166262 Aug 23 20:29 FULL-INDEX
-rw-rw-rw- 1 demo guest 18 Aug 23 20:42 file1
drwxrwxrwx 3 demo guest 1024 Aug 23 20:44 newdir
-rw-rw-rw- 1 demo guest 18 Aug 23 20:42 newfile
-rw-rw-rw- 1 demo guest 18 Aug 23 20:43 newfilee2
-rw-rw-rw- 1 demo guest 19 Aug 23 20:23 text
./newdir:
total 6
drwxrwxrwx 2 demo guest 24 Aug 23 20:41 new1dir
-rw-rw-rw- 1 demo guest 18 Aug 23 20:43 newfile2
-rw-rw-rw- 1 demo guest 18 Aug 23 20:44 newfile3
./newdir/new1dir:
total 0
$
A fįjlok mįsolįsįra a cp (copy) parancs szolgįl. Fontos különbség a DOS-hoz szokott felhasznįló szįmįra, hogy itt mindenképp legalįbb két argumentumot meg kell adni, azaz a DOS alatt szokįsos copy fįjl megadįsmód nem megy, a célfįjlt vagy katalógust is meg kell adni: az elõzõ DOS példa ekvivalense ķgy a cp fįjl . parancs, ahol expliciten megneveztük az aktuįlis katalógust, mint célkatalógust.
A cp parancs mūködése hasonló a mv parancshoz, azaz itt is fįjlt fįjlba mįsol, ha a céltįrgy fįjl, illetve katalógusba helyez, ha a céltįrgy katalógus.
Fįjlokat az rm (remove) paranccsal törölhetünk, természetesen most is megadhatunk több fįjlnevet a paraméterlistįn. Az rm parancs opciói közül gyakran fontos lehet a -f: ennek hatįsįra az egyébként ķrįsvédett fįjlokat is törli az rm. A -i (interactive) opció hatįsįra a rendszer egyenként visszaigazolįst kér a fįjlok törlése elõtt. (Szįmos rendszerben ugyanez az opció mūködik a mv és a cp parancsnįl is.)
Végül egy igen hatįsos, de egyben igen veszélyes opcióról: a -r hatįsįra rekurzķv módon törlõdik mind a megnevezett katalógus a benne lévõ fįjlokkal, mind a fįjlhierarchiįban belõlük szįrmazó összes katalógus és įllomįny.
Ellentétben a DOS-sal, a UNIX-ban a fįjlok törlése visszafordķthatatlan folyamat - KITÖRÖLT FĮJLT SEMMILYEN MÓDON NEM LEHET HELYREĮLLĶTANI!!! Éppen emiatt is, egyes parancsértelmezõkben lehetõség van olyan konfigurįlįsra, hogy törlést, felülķrįst, és mįs visszafordķthatatlan mūveleteket ne hajtson végre a rendszer, hanem minden esetben kérjen visszaigazolįst a "gyanśs" mūveletekrõl. E célt szolgįlja a fentiekben emlķtett -i opció is.
Lįncok létrehozįsa: az ln parancs
A UNIX fįjlrendszerének egyik jellemzõ sajįtossįga a lįncolįs (linkelés) fogalma, ami a DOS és mįs egyfelhasznįlós operįciós rendszerek alatt nem talįlható meg. E mechanizmus arra szolgįl, hogy egy adott įllomįnyt több néven is el lehessen érni az įllomįnyrendszerben. Ha példįul van egy įllomįnyunk text néven, akkor az ln parancs segķtségével elérhetjük, hogy mondjuk szoveg néven is hivatkozhassunk rį.
$ ln text szoveg
$ ls -l
total 364
-rw-rw-rw- 1 demo guest 166262 Aug 23 20:29 FULL-INDEX
-rw-rw-rw- 1 demo guest 18 Aug 23 20:42 file1
drwxrwxrwx 3 demo guest 1024 Aug 23 20:44 newdir
-rw-rw-rw- 1 demo guest 18 Aug 23 20:42 newfile
-rw-rw-rw- 1 demo guest 18 Aug 23 20:43 newfilee2
-rw-rw-rw- 2 demo guest 18 Aug 23 20:59 szoveg
-rw-rw-rw- 2 demo guest 18 Aug 23 20:59 text
$
A lįncolįs tényérõl az ls -l parancs kimenetét vizsgįlva gyõzõdhetünk meg: a valamilyen mįs néven is lįncolt įllomįnyok lįncszįma (link count) egynél nagyobb érték.
Lįtható, hogy text és szoveg minden paramétere azonos, ugyanakkor lįncszįmuk egynél nagyobb, s ahogy egyre több lįncolįst hajtunk rajtuk végre, egyre jobban nõ.
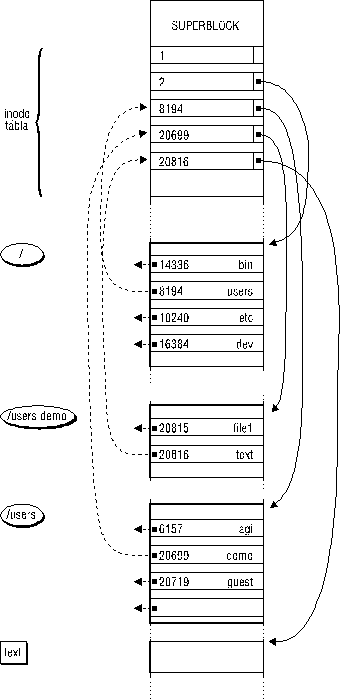
A lįncolįs mibenlétének megértéséhez érdemes egy kicsit részletesebben megismerkedni a UNIX fįjlrendszerének belsõ szerkezetével. A 6. įbra mutatja a UNIX fįjlrendszer belsõ felépķtését. Minden UNIX fįjlrendszer elején megtalįlható az śgynevezett szuperblokk, amelyik a fįjlrendszer legfontosabb adatait, a belsõ tįblįk és azonosķtók méretét, stb. tartalmazza. Ezt követi az śgynevezett inode tįbla, végül a ténylegesen felhasznįlható lemezterület, ahol az įllomįnyok įltal lefoglalt és a még szabad lemezblokkok vegyesen helyezkednek el.
Az inode név az index-node bevett rövidķtése, és a fįjlrendszer kialakķtįsįnak fontos tényére utal, nevezetesen arra, hogy az įllomįnyok jellemzõit tartalmazó inode-okat indexként hasznįljįk a rendszerprogramok. Az inode tįbla egy fix méretū tįbla, fix hosszśsįgś rekordokkal, s minden egyes fįjlhoz, lett légyen az közönséges adatįllomįny, vagy katalógus, egy és csakis egy inode bejegyzés tartozik. Az inode tartalmazza az adott fįjlra vonatkozó összes lényeges informįciót, az įllomįny méretét, tķpusįt, tulajdonosįt és csoportjįt, a hozzįférési jogokat, és az įllomįnyt alkotó lemezblokkok fizikai elhelyezkedését a lemezen. Egy informįció hiįnyzik csak az inodeból, mégpedig a szóbanforgó įllomįny neve: ezt az informįciót a katalógus(fįjl) tartalmazza.
A katalógusfįjlban minden egyes fįjlhoz, ami az adott katalógusban szerepel, egy bejegyzés tartozik. E rekord nem tartalmaz mįst, mint az įllomįny inode szįmįt, és az įllomįny nevét. Nézzük meg ezek utįn, mi történik akkor, amikor mondjuk a /users/demo/text fįjlt szeretnénk kilistįzni? (Segķtségképpen olyan formįban (a -i [inode] opcióval) listįztuk ki a szóban forgó fįjlokat, hogy az inode értéke is szerepeljen az elsõ oszlopban.)
$ ls -ial /
total 4926
2 drwxr-xr-x 19 root root 3072 Aug 23 13:40 .
2 drwxr-xr-x 19 root root 3072 Aug 23 13:40 ..
14336 drwxrwxrwx 4 root sys 2048 May 14 21:23 bin
16384 drwxrwxrwx 13 root sys 4096 Aug 10 20:24 dev
10240 drwxr-xr-x 14 root other 5120 Aug 23 19:36 etc
17 -rwxr-xr-x 1 root sys 2351104 Sep 7 1992 hp-ux
12499 drwxrwxrwx 2 root other 24 Apr 22 1992 lost+found
2 drwxrwxrwx 3 root root 2048 Aug 23 22:17 tmp
8194 drwxr-xr-x 43 root sys 1024 Aug 17 09:40 users
2 drwxr-xr-x 31 root sys 1024 Aug 10 16:59 usr
$ ls -ial /users
total 94
8194 drwxr-xr-x 43 root sys 1024 Aug 17 09:40 .
2 drwxr-xr-x 19 root root 3072 Aug 23 13:40 ..
6517 drwxr-xr-x 3 agi users 1024 Jun 29 09:56 agi
20699 drwxr-xr-x 3 demo users 1024 Aug 23 21:00 demo
20719 drwxr-xr-x 4 guest users 1024 Aug 10 19:17 guest
..
$ ls -ial /users/demo
total 378
20699 drwxr-xr-x 3 demo users 1024 Aug 23 21:00 .
8194 drwxr-xr-x 43 root sys 1024 Aug 17 09:40 ..
..
20818 -rw-rw-rw- 1 demo guest 18 Aug 23 20:42 file1
..
20816 -rw-rw-rw- 2 demo guest 18 Aug 23 20:59 text
$
A rendszer elõször megkeresi a gyökér katalógus inode-jįt, ez a mįsodik inode (#2). Az inode rekordból kikeresi, hogy a lemezen fizikailag hol helyezkedik el maga a / katalógusfįjl, ami a gyökérkatalógusban lévõ fįjlok nevét adja meg. Megnyitja e katalógust, megkeresi benne a users bejegyzést, megnézi az ahhoz tartozó inode szįmot (#8194), ezt indexként hasznįlva az inode tįblįban megkeresi a /users katalógusra vonatkozó bejegyzést is. Az ebben az inode-ban tįrolt adatok alapjįn megkeresi a lemezen a /users katalógusfįjlt, megnyitja, és megkeresi benne a demo bejegyzést, az ahhoz tartozó inode szįm (#20699) alapjįn az inode tįblįban megkeresi a megfelelõ bejegyzést, kiolvassa belõle a /users/demo katalógusfįjl helyét, megnyitja a katalógust, megkeresi benne a text fįjlra vonatkozó bejegyzést, a hozzįtartozó inode szįm (#20816) alapjįn megkeresi az inode-ot, és annak alapjįn megnyitja a tényleges fįjlt.
Az egész módszernek az a lényege, hogy hįrom szintū az įllomįny nyilvįntartįs, az inode-ok, a katalógusfįjlok és a tényleges fizikai įllomįnyok között oszlik meg az informįció, s a katalógusfįjlok csak név és inode informįciót tartalmazzįk, az inode-ok pedig minden egyebet. Ennek alapjįn érthetõ meg igazįn a lįncolįs mechanizmusa: amikor egy fįjlt linkelünk, nem történik mįs, mint hogy valamelyik katalógusban egy olyan bejegyzést hozunk létre, ami egy mįr létezõ, és mįs néven is hivatkozott inode-ra mutat. Maga a fįjl vįltozatlan marad, a lįncolįs tényét kizįrólag az śj katalógus bejegyzés, és az inode-ban megnövelt lįncszįm jelzi.
Felmerülhet a kérdés, mi van akkor, ha egy lįncolt fįjlt törlünk? A fentiek ismeretében könnyū a vįlasz: törléskor a rendszer mindig a lįncszįm vizsgįlatįval kezd, ha annak értéke egynél nagyobb, akkor csak a fįjlnév bejegyzést törli az adott katalógusból, és eggyel csökkenti a lįncszįmot. Ha a lįncszįm egy, akkor ténylegesen is törli az įllomįnyt, azaz nemcsak az (utolsó) katalógus bejegyzést szünteti meg, hanem az inode tįblįból is törli a fįjlra vonatkozó bejegyzést.
Nem beszéltünk még arról, hogy mire is jó tulajdonképpen a lįncolįs? Két nagy elõnye van, az egyik a névütközések feloldįsa, a mįsik a helytakarékossįg.
A névütközések problémįja onnan ered, hogy a UNIX verziók eltérõ fejlõdése miatt ugyanolyan néven kezdtek nevezni mįs-mįs parancsokat. Legismertebb példa erre az rsh parancs, ami a System V alapś rendszerekben a restricted shell-t jelenti (ez a szokvįnyos Bourne shell egy korlįtozott szolgįltatįsokkal bķró vįltozata), a BSD alapś UNIX rendszerekben viszont a remote shell rövidķtése, ami a tįvoli gépeken történõ parancsvégrehajtįsra szolgįl. Mivel a mai rendszerekben mind a két parancs szerepel, įltalįban csak a katalógusokban definiįlt keresési sorrend dönti el, hogy az rsh parancs kiadįsakor melyik indul el a kettõ közül (mindig a mįsik, mint amelyiket akartuk, errõl sajįt tapasztalatunk alapjįn biztosķtjuk a Nyįjas Olvasót...). Ha viszont valamelyiket egy eltérõ névvel lįncoljuk, akkor a névütközés problémįjįt feloldottuk. A restricted shell rendszerint a /usr/bin könyvtįrban talįlható, mķg a remote shell a /usr/ucb alatt. Adjuk ki az alįbbi parancsot (Ehhez superuser jogok kellenek!):
$ ln /usr/ucb/rsh /usr/bin/remsh
$
E parancs hatįsįra a tovįbbiakban remsh néven hķvhatjuk a remote shell-t, rsh néven a mįsikat, s a módszer a katalógusok keresési sorrendjétõl függetlenül mūködni fog.
A linkek mellett szóló mįsik érv a helytakarékossįg. Tegyük fel, hogy van két C nyelvū programunk, amelyek igen hasonló funkciókat lįtnak el, lényegtelen eltérésekkel. Megtehetjük azt, hogy mindkettõt külön-külön lefordķtjuk, keletkezik két éktelen nagy binįris programunk, különbözõ néven. Ennél sokkal jobb megoldįs, ha egy közös, némileg ugyan nagyobb forrįskódot fordķtunk le egy példįnyban, a keletkezett binįris végrehajtható program nevét pedig a mįsik programnévhez lįncoljuk. (A program futįs közben el tudja dönteni, hogy milyen néven hķvtįk, s az annek megfelelõ végrehajtįsi įgakra futhat.) Lįtszik, hogy ez esetben csak egy darab nagyméretū program foglal helyet a lemezen, a linkelés helyigénye elhanyagolható (gyakorlatilag a mįsodik név katalógus-bejegyzése, ami tipikusan 16 bįjt.) A legszebb példa minderre éppen a mv, cp és ln parancs esete. E hįrom program, mint mįr lįttuk, erõsen hasonló funkciókat lįt el, a paraméterek kiértékelése, szįmos opció, az inode-okon és a katalógusokon végrehajtandó mūveletek nagy része közös, tehįt a hįrom program viszonylag jól integrįlható. A legtöbb rendszerben ezért egy közös binįris végrehajtható program végzi mindhįrom tevékenységet.
$ cd /bin
$ ls -il mv cp ln
12312 -r-xr-xr-x 3 bin bin 13880 Mar 27 15:07 cp
12312 -r-xr-xr-x 3 bin bin 13880 Mar 27 15:07 ln
12312 -r-xr-xr-x 3 bin bin 13880 Mar 27 15:07 mv
$
Mint a fenti példįn is lįtható, körülbelül 26 kbįjt helyet nyertünk, hiszen csak egy példįnyban létezik a 13 kbįjt méretū binįris fįjl, s ezen kķvül csak a két link 32 bįjtja foglal helyet.
Ez az eljįrįs egyébként nemcsak binįris végrehajtható fįjloknįl, de shellscript-eknél is alkalmazható.
Még egy dologról emlķtést kell itt tennünk, s ez a szimbolikus lįnc (symbolic link) fogalma. A UNIX rendszer kétféle lįncolįsi eljįrįst ismer, a merev és a lįgy lįncolįst (hard and soft link). Az elõbbiekben a merev lįncolįssal foglalkoztunk, ennek legfõbb jellemzõje az, hogy a lįncolt fįjl teljesen egyenértékū az eredetivel, hiszen egyazon inode-ra mutat két egyenértékū katalógus bejegyzés, amelyek között nem lehet különbséget tenni.
A "lįgy lįncolįs", vagyis a szimbolikus link viszonylag késõi śjķtįs a UNIX-ban, a SunOS operįciós rendszerbõl terjedt el az elmślt években, de mįra mįr szabvįnyos eleme a UNIX-nak. Lényege, hogy a szimbolikus link katalógus bejegyzése nem a fįjl inode-jįra mutat, hanem egy olyan különleges fįjlra, ami a lįncolt fįjl nevét tartalmazza. Szimbolikus linket szintén az ln paranccsal hozunk létre, de a -s opciót is meg kell adni:
$ ln -s /usr/lib/sendmail.cf sendmail.cf
$ ls -l
total 364
-rw-rw-rw- 1 demo guest 166262 Aug 23 20:29 FULL-INDEX
-rw-rw-rw- 1 demo guest 18 Aug 23 20:42 file1
drwxrwxrwx 3 demo guest 1024 Aug 23 20:59 newdir
-rw-rw-rw- 1 demo guest 18 Aug 23 20:42 newfile
-rw-rw-rw- 1 demo guest 18 Aug 23 20:43 newfilee2
lrwxrwxrwx 1 demo guest 20 Aug 23 23:14 sendmail.cf ->
/usr/lib/sendmail.cf
-rw-rw-rw- 2 demo guest 18 Aug 23 20:59 text
$
Lįtható, hogy a lįncszįm ebben az esetben nem vįltozott (az csak a hard link esetén nõ), a fįjltķpusnįl egy 'l' betū szerepel, jelezvén, hogy szimbolikus linkrõl van szó, s a fįjlnévnél a '->' karakterek jelzik, hogy melyik fįjlhoz van lįncolva az įllomįny.
Ha a példįnkban szereplõ sendmail.cf fįjlt meg akarja nyitni egy prog-
ram, akkor a következõ történik: az elõzõekben vįzolt módon eljut a /users/demo/sendmail.cf fįjl inode-jįig; észreveszi, hogy szimbolikus link a fįjl tķpusa; megnyitja a fįjlt; kiolvassa a tartalmįt, ami jelen esetben /usr/lib/sendmail.cf; a tovįbbiakban ezt a fįjlt keresi és nyitja meg, a mįr ismert módon.
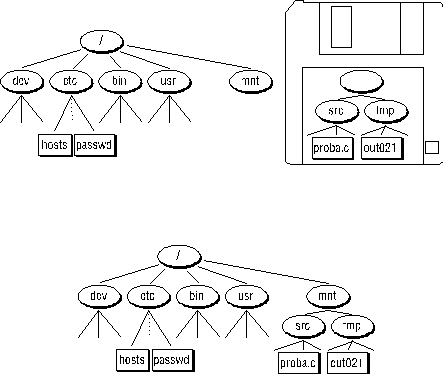
Mire jó a szimbolikus link? Legfontosabb elõnye az, hogy lehetõvé teszi különbözõ fįjlrendszerek közti lįncolįst. Ennek megértéséhez néhįny szóval meg kell emlķteni a UNIX fįjlrendszer egy érdekes tulajdonsįgįt, mégpedig a mountolhatósįg fogalmįt. A UNIX fįjlrendszere, ahogy azt a felhasznįló szerves egésznek lįtja, nem feltétlenül egységes fizikai szinten is. Ha példįul több merevlemez van a gépben, ezeken külön-külön UNIX fįjlrendszerek vannak installįlva, hasonlóképpen, egy CD-n, vagy egy floppy diszken is. Mountolįsnak hķvjįk azt a tevékenységet, amikor egy ilyen különįlló fįjlrendszert becsatolunk egy mįr meglévõhöz. A 7.įbrįn egy olyan példįt mutatunk be, ahol egy floppyn lévõ UNIX-os fįjlrendszert csatolunk be a gazdagép UNIX fįjlrendszerébe, a /mnt katalógus alį. A tovįbbiakban a floppyn lévõ fįjlrendszer gyökérkatalógusa a /mnt hivatkozįssal érhetõ el, a floppyn lévõ /src katalógus /mnt/src néven és ķgy tovįbb. Magįról a mountolįsról több szót nem ejtünk, mert a kérdés leginkįbb a rendszeradminisztrįtorokat érinti, a felhasznįló szempontjįból a becsatolįs észrevehetetlen kell hogy legyen. A fentiek annyiban érdekesek a szįmunkra, hogy merev lįncolįst nem lehet két különbözõ mountolt fįjlrendszer között létrehozni. A linkelés mechanizmusa ugyanis arra épül, hogy az inode-ok egy įllomįnyrendszeren belül egyértelmūen azonosķtjįk a fįjlokat, azaz ugyanazon inode-ra történõ hivatkozįs ugyanazt a fįjlt jelenti. Mivel azonban minden egyes önįllóan becsatolható fįjlrendszerben független a szįmozįs (mindegyikben 2 a root inode stb), az inode érték önmagįban nem nyśjt elégséges informįciót arra nézve, hogy a keresett fįjl a teljes įllomįnyrendszerben hol talįlható. Ezért ha fįjlrendszerek közti lįncolįst próbįltunk meg, az alįbbi, vagy hasonló értelmū hibaüzenetet kapunk:
$ ln /usr/users/janos/proba proba
ln: different file system
$
A fenti problémįt kikerülhetjük a szimbolikus lįncolįssal, mert a szimbolikus linkben szereplõ név akįrhova, mįs įllomįnyrendszerbe, nemlétezõ, vagy pillanatnyilag el nem érhetõ helyre is mutathat.
A merev lįncolįs mįsik hįtrįnya, hogy csak egyedi fįjlok linkelését teszi lehetõvé, katalógusokét nem. Szimbolikus link alkalmazįsįval egész katalógusokat lįncolhatunk įt egy paranccsal egy mįsik fįjlrendszerbe, ami gyakran hasznosnak bizonyulhat, ha példįul a jobb terhelésszétosztįs miatt śjra kell strukturįlni a fįjlrendszert, és egész alkalmazįscsomagokat helyezünk įt mįs fįjlrendszerbe, ugyanakkor mindezt a felhasznįló szįmįra észrevétlenül akarjuk végrehajtani.
{kind=link}
{kind=link}